Mechanismen der sich selbstverstärkenden Software-Erosion
Es liegt auf der Hand, dass die Meyers dieser Erde, die solche Systeme von Anfang an begleitet und tiefes Systemwissen aufgebaut haben, immer weniger werden. Entweder gehen sie in Rente oder haben irgendwann zu einer anderen Firma gewechselt. Typischerweise ist auch die Dokumentation eher dünn, die Systempflege hat im Prinzip ja funktioniert, die Erstellung einer umfassenden Dokumentation wäre sehr teuer gewesen. Auf den jungen, fähigen Nachwuchs wirken solche Systeme mit veralteter Technologie eher abstoßend. Dem Autor ist ein Fall bekannt, wo auf ein altes, aber sehr wertschöpfendes System mehrfach Nachwuchs zur Einarbeitung angesetzt wurde. Dieser verabschiedete sich nach wenigen Wochen dankend wieder, um sich anderen, deutlich reizvolleren und karriereförderlicheren Aufgaben zu widmen.
Aber auch hartgesottene Entwickler haben schwer zu kämpfen und berichten, sobald sie ihre Sprache wiedergefunden haben, von überbordender Komplexität, verblüffenden Nebenwirkungen und irrsinnigen Seiteneffekten, kryptischen Konstrukten, labyrinthischen Abläufen und Strukturen, Doppelt- und Dreifachimplementierungen und großen Brachflächen von vermutlich totem Code.
Aber wie kommen die da hinein? Irgendjemand muss die ja mal eingebaut haben – bei Neusystemen kennt man so etwas eher nicht.
Die Antwort lautet kurz und bündig: Komplexität ist selbstverstärkend.
Eine ideal informierte Entwicklerin navigiert souverän im Code des Systems, grenzt spielend die für die Aufgabe relevanten Codestellen vom Restcode ab, übersieht keine relevante Codestelle, kennt und behandelt alle Seiteneffekte, kann die Auswirkung ihrer Änderung auf Laufzeit und ggf. Race Conditions klar abschätzen und weiß nach zehn Jahren noch genau, was sie damals geändert hat und warum. Selbstverständlich gelingt es ihr in ein oder zwei Kaffeepausen, all diese Fakten ihren Kolleginnen und Kollegen gut verständlich mitzuteilen. Dafür bräuchte unsere Entwicklerin allerdings ein Gedächtnis, das eine ganze Elefantenherde vor Neid hellgrau erblassen ließe. Oder ein extrem gutes Dokumentationssystem, das, hervorragend navigierbar und abfragbar, für ein Änderungsvorhaben auf den Punkt genau die relevanten Informationen liefert und neue Informationen aus der Änderung auch wieder aufnimmt. Und natürlich genug Zeit und Motivation, ihre Änderung dort tatsächlich auch wieder einzupflegen.
Ein Entwickler aus dem Kreis der gewöhnlichen Sterblichen hat all das aber bestenfalls in seinen kühnsten Träumen. Er sieht nur einen Ausschnitt des Systems, speziell wenn er nicht von Anfang an mitentwickelt hat, und hat auch nicht die Zeit, sich einen ausreichenden Überblick zu verschaffen. Weil seine Informationslage alles andere als perfekt ist, sondern eher mit einem Marsch im Urwald mit geringer Sichtweite vergleichbar, muss er sich konservativ verhalten. Lieber implementiert man eine Funktion noch einmal, als sie im System zu suchen; eventuell kopiert man eine Funktion und passt sie etwas an. Funktionen, die man nicht mehr braucht, bleiben lieber stehen. Wer weiß, wer sie noch alles braucht. Datenstrukturen erweitert man am besten nach Bedarf, statt eigene zu implementieren, dann ist man sicher, dass der bestehende Transportpfad quer durchs System funktioniert. Und die Daten, die man braucht, sind ohnehin in der Benutzeroberfläche verfügbar. Wieso also mühsam aus fernliegenden Systemteilen holen; so ein bisschen Funktionalität in der UI verträgt das System schon.
Folge: die Komplexität steigt. In der nächsten Änderung: die Komplexität steigt. Und zwar diesmal noch ein wenig stärker als letztes Mal. Insgesamt beschleunigt sich der Verfall der Systemstruktur immer mehr und damit auch die Undurchsichtigkeit, die aus gestiegener Komplexität resultiert. Komplexität ist selbstverstärkend. Das liegt nicht an der Entwicklerin. Sie kennt die bewährten Architektur- und Designprinzipien sehr genau und will sie auch anwenden. Sie hat aber wegen der Undurchsichtigkeit des Systems dazu keine Chance und kann, auch aus Budgetgründen, das Risiko einer tiefgreifenden Änderung, womöglich mit umfangreichen Nebenwirkungen, nicht wagen. Dieser Mechanismus ist letztlich der Grund dafür, dass eigentlich alle Altsysteme in verschiedenen Graden verwickelt, verworren, verwunschen oder gar in einem verzweifelten Zustand sind – je nach Historie.
Kosteneffiziente Gegenmaßnahmen bei der Software-Modernisierung und -Pflege
Es gibt aber durchaus Gegenmaßnahmen. Auf diesen Systemverfall kann man auch mit überschaubarem Pflegebudget positiv Einfluss nehmen.
Dynamische Systemdokumentation
Schon ein einfaches Wiki oder ein Tracker hilft, problematische Stellen und Verbesserungsansätze zu dokumentieren und immer dann, wenn Codeteile ohnehin geändert und getestet werden müssen, diese Verbesserungen mit vorzunehmen. Auf diese Weise lässt sich in kleinen Schritten Komplexität auch wieder abbauen. Wichtig ist dabei der Bezug der dokumentierten Stellen zum Code oder zu Funktionalitäten, um für geplante Änderungen passende Zusatzverbesserungen zu finden.
Oben wurde unzureichende Dokumentation als wesentlicher Beitrag zum Systemverfall angegeben. Es ist deswegen sinnvoll, die Struktur einer dynamischen Dokumentation zu definieren und bereitzustellen. Entwickler gewinnen während ihrer Arbeit ohnehin umfangreiche Erkenntnisse über das System und dokumentieren diese nun im bereitgestellten System anstatt auf Schmierzetteln, die sie nach getaner Arbeit wegwerfen. Damit wächst die Dokumentation inkrementell. Sehr hilfreich ist es, wenn neu hinzukommende Entwickler ihre Lernkurve in dieses System einbringen. Es ist aber keineswegs trivial, ein solches System so zu strukturieren, dass es langfristig nützlich bleibt und nicht einfach zu einer Daten-Müllhalde wird.
Abschnittweise Tests bei tiefgreifenden Änderungen
Ein Grundproblem der Systemvereinfachung besteht darin, dass man bei tiefgreifenden Änderungen einen umfangreichen Systemtest durchführen muss, der meist sehr teuer ist und bis zur Stabilität ggf. mehrfach wiederholt werden muss. Deswegen baut man vor der tiefgreifenden Änderung das System so um, dass A/B-Vergleiche von geänderten und ungeänderten Teilen möglich sind.
Martin Fowler empfiehlt hier die Patterns EventInterception, Content-Based Router und AssetCapture innerhalb des Migrationsmusters StranglerFigApplication.
Am Übergang zur geplanten Änderung, z.B. der Austausch einer Kommunikationsschicht, fügt man EventInterception und Content-Based Router ein. Der Content-Based Router verzweigt konfigurierbar je nach Anwendungsfall entweder auf den alten oder den neuen Code.
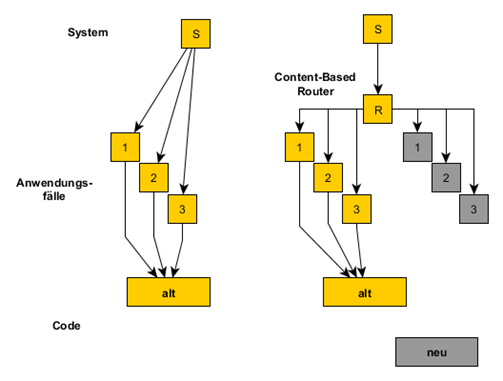
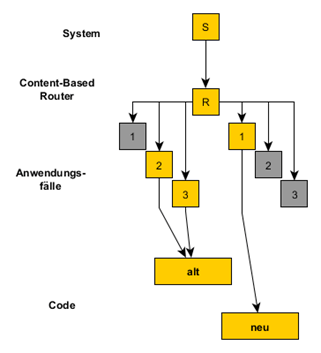
Gleichzeitig partitioniert man die Verzweigung so, dass der größte Teil der Anwendungsfälle den alten Code verwendet. Nur ein definierbarer kleiner Teil verwendet den neuen Code. Anfangs benutzen sogar alle Anwendungsfälle weiter den alten Code. Das ist natürlich eine tiefgreifende Änderung und benötigt zunächst einmal einen Gesamtsystemtest. Dieser sollte rasch stabil werden, weil sich die Funktionalität nicht geändert hat. Anschließend lenkt man einen kleinen Teil der Anwendungsfälle auf den neuen Code und testet nur mit den Testfällen, die zu diesen Anwendungsfällen gehören. Dadurch ist die Stabilisierung des neuen Codes weniger aufwendig. Immer wenn weitere Anwendungsfälle ohnehin getestet werden müssen, testet man sie mit Hilfe des Content-Based Router im A/B-Vergleich und kann sie anschließend mit dem neuen Code betreiben.
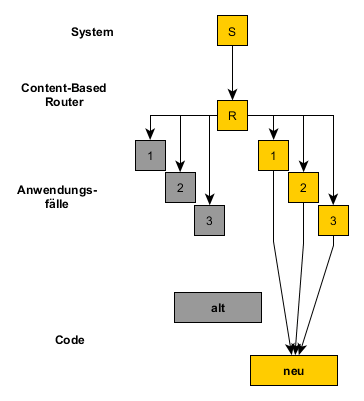
Nach einiger Zeit sind alle Anwendungsfälle mit geringem Zusatzaufwand behandelt, der alte Code ist obsolet und kann entfernt werden. Der Content-Based Router verbleibt u.U. im System, für den Fall, dass der dahinter liegende Teil (im Beispiel die Kommunikationsschicht) ein weiteres Mal erneuert wird.
Einschätzung des Software-Erosionsgrades
Wie findet nun der Verantwortliche eines Altsystems heraus, an welchem Punkt dieser selbstbeschleunigenden Abwärtsentwicklung sich sein System befindet?
Die Antwort auf diese Frage hilft ihm, die richtigen Maßnahmen zum richtigen Zeitpunkt zu ergreifen, um das System bis zum geplanten Endzeitpunkt nutzbar zu halten. Anmerkung: Und bitte deutlich darüber hinaus, denn das Nachfolgesystem kommt in der Regel nie so schnell wie eigentlich geplant.
Für den Verantwortlichen deutlich sichtbar sind die Pflegeaufwände, die Umsetzungsdauern und die Zahl der Testschleifen, bis eine Änderung stabil ist. Dabei wird eingearbeitetes Personal vorausgesetzt. Steigt die Kurve dieser Faktoren im Lauf der Jahre an, so deutet das nicht etwa auf gewachsene Trägheit der Pflege-Entwickler hin, sondern auf immer weiter steigende Komplexität, die anhand der Kurve auch extrapolierbar sein dürfte.
Analog verfährt man mit der Zahl der Nachkorrekturen nach einer Änderung als Maß für nicht vorhersehbare Seiteneffekte.
Für die Kostenplanung einer Einzeländerung empfiehlt es sich, vorab die voraussichtlich betroffenen Codebereiche zu identifizieren und in der Versionsverwaltung nachzusehen, ob dort sehr viele Fehler korrigiert wurden. Wenn ja, sind dort weitere Probleme zu erwarten. In diesem Fall ist ein Risikofaktor in der Kosten- und Zeitplanung sinnvoll.
Ein kritischer Punkt ist erreicht, wenn sich das System bei Änderungen als “nicht stabilisierbar” oder “nur mit Glück stabilisierbar” erweist. Ebenso ist ein kritischer Punkt erreicht, wenn die letzten Knowhow-Träger in Rente gehen oder ausfallen und keine Nachfolger aufgebaut wurden.
In diesem Fall ist die nächste Maßnahmenstufe sinnvoll, nämlich die Analyse des Systems zur Vorbereitung einer System-Modernisierung. Danach ist deutlich klarer, wie tragfähig das System noch ist.
Sollte es sogar so weit sein wie in einem unserer Kundenprojekte, dass bei jedem Windows 10-Update nicht klar ist, ob das System danach überhaupt noch läuft, sollten Sie definitiv rasch den Modernisierungsdienstleister Ihres Vertrauens anrufen.